Vllm 分布式推理:突破大模型服务的内存瓶颈
本文是Distributed Inference with vLLM的中文翻译版本,内容有删减
Motivation
当前的大语言模型(LLM),在推理阶段面临着巨大的内存需求。随着模型参数的增加,单个GPU往往无法满足其内存需求,导致推理过程中出现CUDA out of memory错误。为了解决这个问题,vLLM采用了两种主要策略:
- Reduce Precision(降低精度) – 利用FP8和更低位数的量化方法可以减少内存使用。然而,随着模型参数超过数百亿时,这种方法可能会影响准确性和可扩展性,单靠它并不足以解决问题。
- Distributed Inference(分布式推理) – 将模型计算分散到多个GPU或节点上,可以实现可扩展性和效率。这就是张量并行和流水线并行等分布式架构发挥作用的地方。
vLLM 架构与大语言模型推理挑战
与大语言模型训练相比,大语言模型推理面临独特的挑战:
- 推理需要低延迟和动态工作负载处理,而训练则纯粹关注已知静态形状的吞吐量。
- 推理工作负载必须有效管理KV缓存、推测解码和预填充到解码(prefill-to-decode)的过渡。
- 大模型往往超出单GPU容量,需要先进的并行化策略。
为了解决这些问题,vLLM提供了:
- Tensor parallelism(张量并行) – 在一个GPU节点内将每个模型层分片到多个GPU上。
- Pipeline parallelism(流水线并行) – 将模型层的连续部分分布到多个节点上。
- Optimized communication kernels and control plane architecture(优化的通信内核和控制平面架构) – 最小化CPU开销,最大化GPU利用率。
关于如何在vLLM的部署中如何使用这些技术的详细信息,请参见Distributed Inference and Serving。
vLLM 中的 GPU 并行技术
Tensor Parallelism(张量并行)
问题描述: LLM 模型超出单个GPU容量
随着模型的增长,单个GPU无法容纳它们,这就需要多GPU策略。Tensor parallelism(张量并行)将模型权重分片到多个GPU上,允许并发计算以降低延迟并增强可扩展性。
这种方法最初是在Megatron-LM (Shoeybi et al., 2019)中为训练开发的,已在vLLM中针对推理工作负载进行了调整和优化。
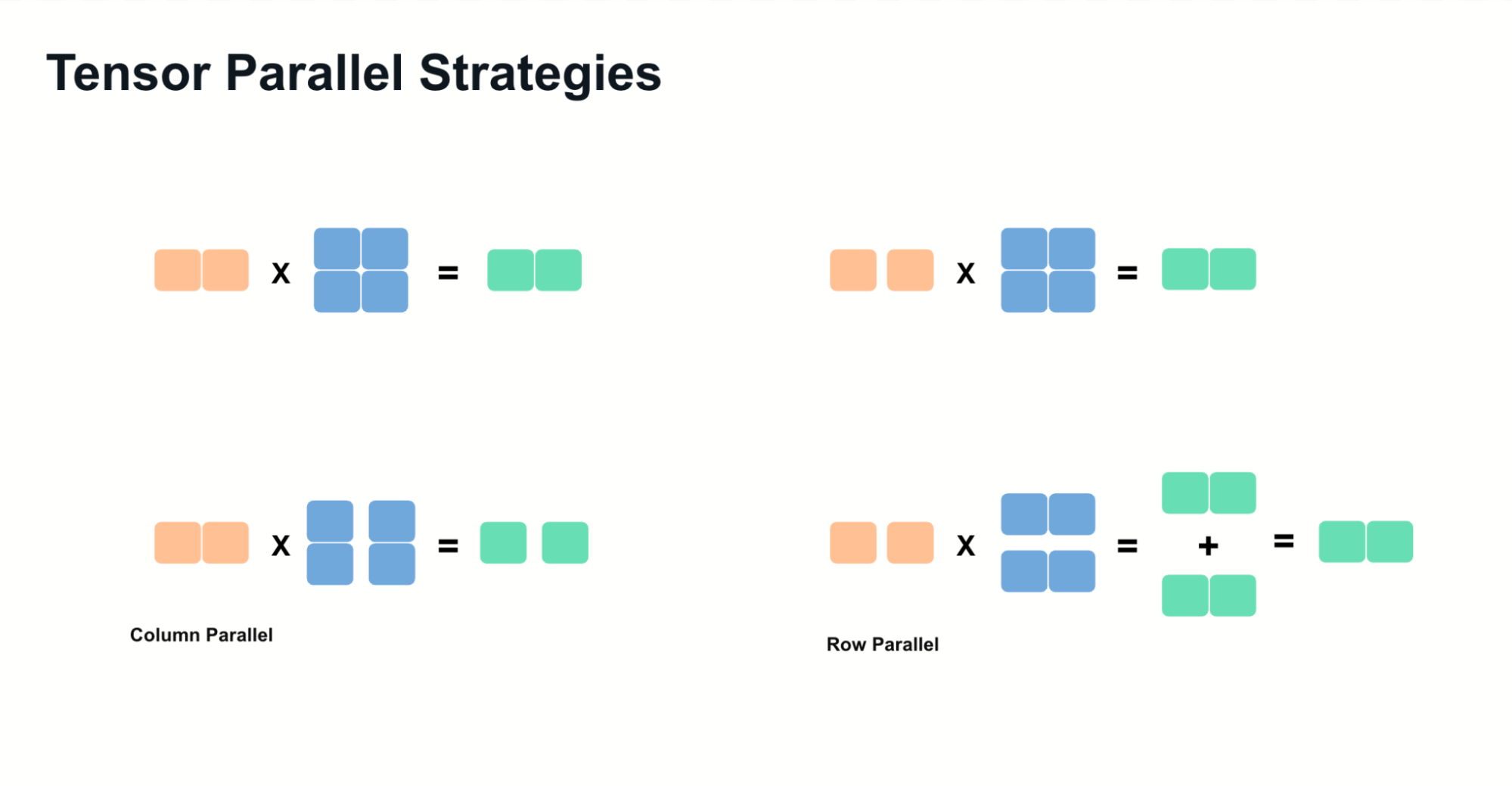
张量并行依赖两种核心技术:
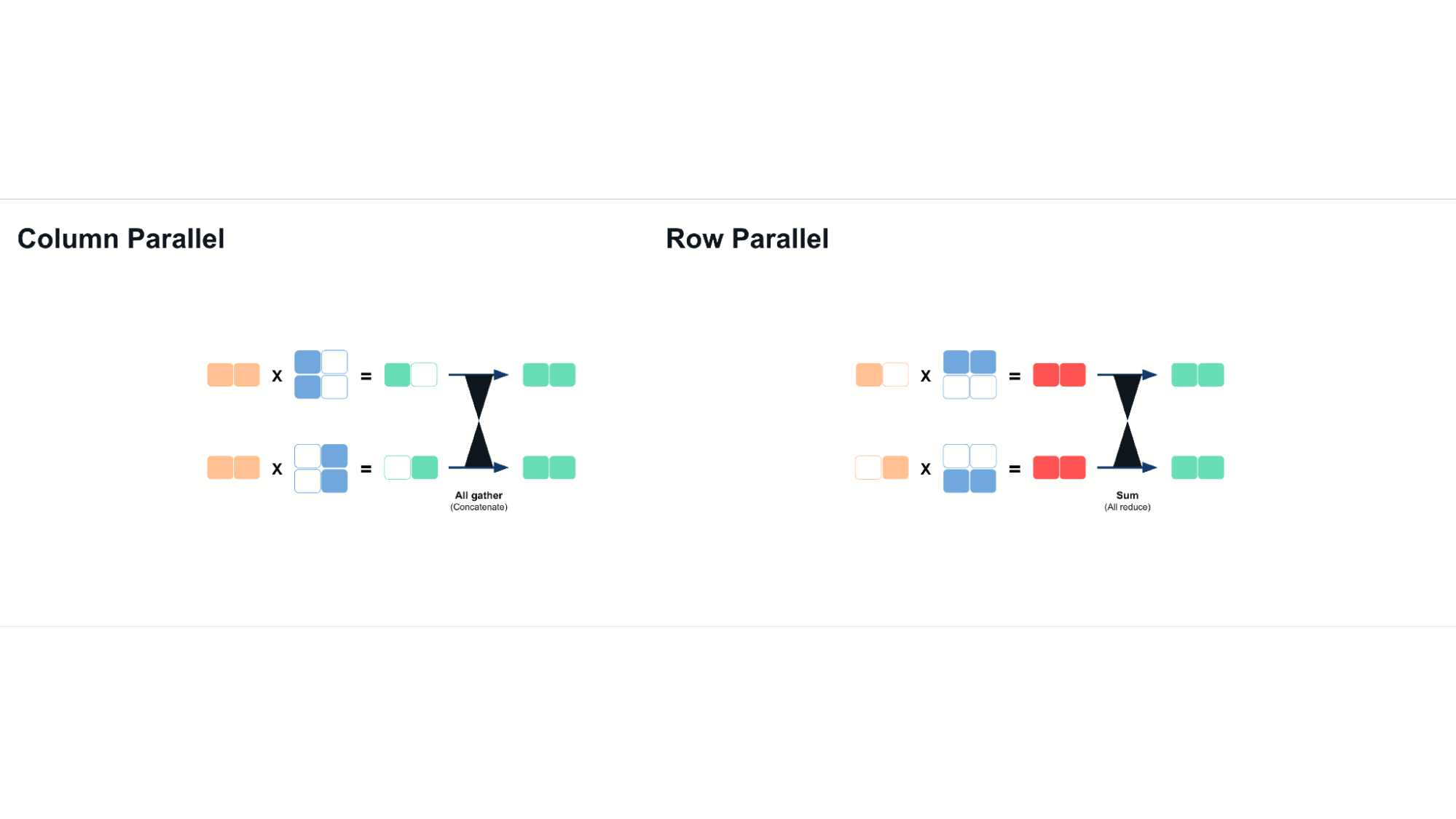
- Column Parallelism(列并行): 沿权重矩阵列分割,计算后拼接结果。
- Row Parallelism(行并行): 沿矩阵行分割,计算后通过求和聚合部分结果。
以 Llama 模型中的 MLP 层为例:
- 列并行 应用于上投影操作
- 元素级激活函数(如 SILU)作用于分片输出。
- 行并行 用于下投影,通过 all-reduce 操作聚合最终结果。
张量并行确保推理计算分布在多个GPU上,最大化可用的内存带宽和计算能力。使用时,我们可以通过有效地乘以内存带宽来实现延迟改进。这是因为分片模型权重允许多个GPU并行访问内存,从而减少单个GPU可能遇到的瓶颈。
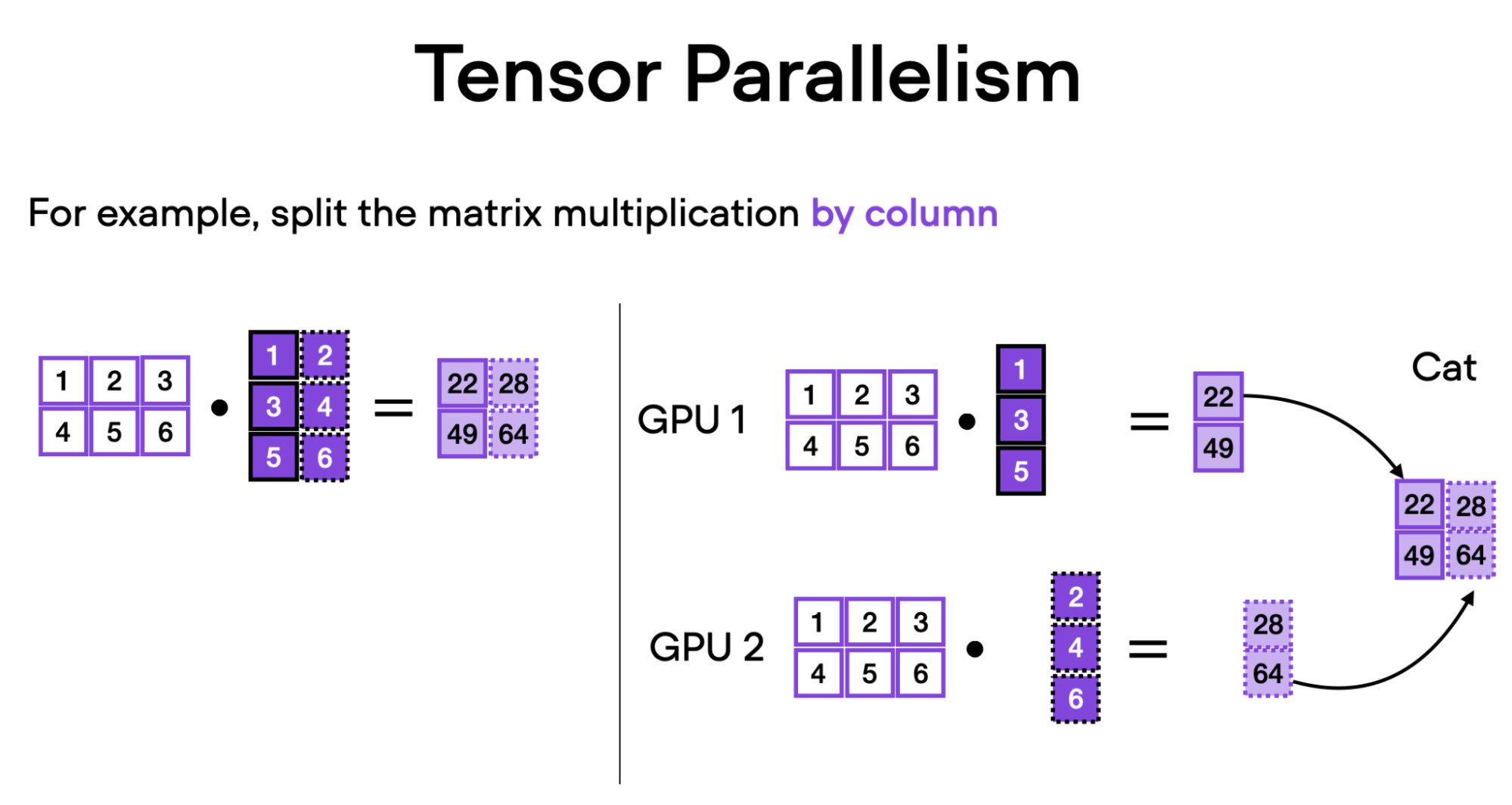 Source: Sebastian Raschka, 2023.
Source: Sebastian Raschka, 2023.
但请注意,张量并行需要高带宽互连(如 NVLink 或 InfiniBand)来最小化由于增加的通信成本而产生的开销。
Pipeline Parallelism(流水线并行)
问题描述: LLM 模型权重超出多 GPU 容量
对于超大模型(例如 DeepSeek R1、Llama 3.1 405B),单个节点可能无法满足需求。流水线并行将模型分片到多个节点上,每个节点处理特定的连续模型层。
工作原理
- 每一个GPU加载并处理一组不同的LLM层。
- 发送/接收操作: 中间激活值随计算进程在 GPU 间传输
与张量并行相比,流水线并行通信开销更低,因为数据传输仅在流水线阶段进行一次。
流水线并行可降低 GPU 内存限制,但不像张量并行那样直接降低延迟。为缓解吞吐效率问题,vLLM 引入 高级流水线调度,通过优化微批处理执行,确保所有 GPU 保持活跃。
张量并行与流水线并行的结合
作为一个通用的经验法则,可以这样考虑并行化 LLM 模型的部署:
- 当GPU互连速度较慢时,在节点之间使用 流水线并行,在节点内部使用 张量并行。
- 当GPU互连速度较快时(例如 NVLink、InfiniBand),张量并行可扩展至跨节点。
- 智能地结合这两种技术可以减少不必要的通信开销,最大化 GPU 利用率。
性能扩展与内存效应
尽管并行化的基本原理指向线性扩展,但实际性能提升可能呈超线性增长,原因在于内存效应。无论是张量并行还是流水线并行,KV 缓存可用内存的增加可能导致吞吐量非线性提升。
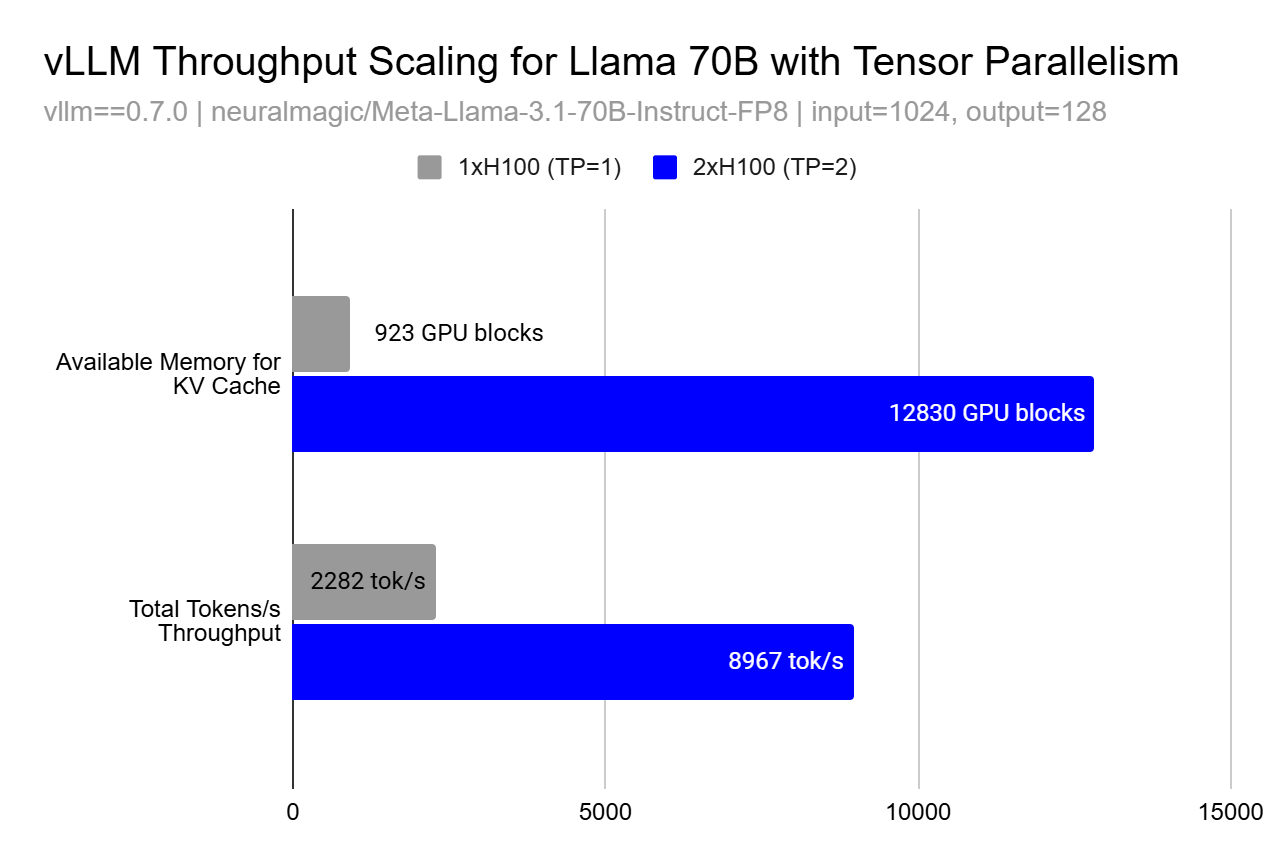
这种超线性效应源于更大的缓存允许处理更多请求(更大批量)并改善内存局部性,从而显著提升 GPU 利用率。例如,从 TP=1 到 TP=2,KV 缓存块数量增加 13.9 倍,token 吞吐量提升 3.9 倍,远超预期的 2 倍线性增长。
进一步阅读
对于那些希望深入了解影响 vLLM 设计的技术和系统的读者:
- Megatron-LM (Shoeybi et al., 2019) 介绍了大语言模型中模型并行的基础技术
- Orca (Yu et al., 2022) 提出了一种使用迭代级调度的分布式服务替代方法
- DeepSpeed 和 FasterTransformer 提供了关于优化变换器推理的互补视角
结论
高效服务LLM模型需要结合张量并行、流水线并行和性能优化(如分块预填充)。vLLM通过利用这些技术实现可扩展的推理,同时确保在不同硬件加速器上的适应性。随着我们继续增强vLLM,了解新发展,如专家并行用于专家混合(MoE)和扩展的量化支持,对于优化AI工作负载至关重要。