k8s 默认的调度器工作机制和策略
参考文章:
https://kubernetes.io/zh-cn/docs/concepts/scheduling-eviction/kube-scheduler/
默认调度器
Kubernetes 调度队列
activeQueue
- 在 activeQ 里的 Pod,都是下一个调度周期需要调度的对象
- 当你在 Kubernetes 集群里新创建一个 Pod 的时候,调度器会将这个 Pod 入队到 activeQ 里面
unschedulableQueue
- 它存储那些由于某种原因而无法被调度的 Pod
- 当一个 unschedulableQ 里的 Pod 被更新之后,调度器会自动把这个 Pod 移动到 activeQ 里,从而给这些调度失败的 Pod “重新做人”的机会
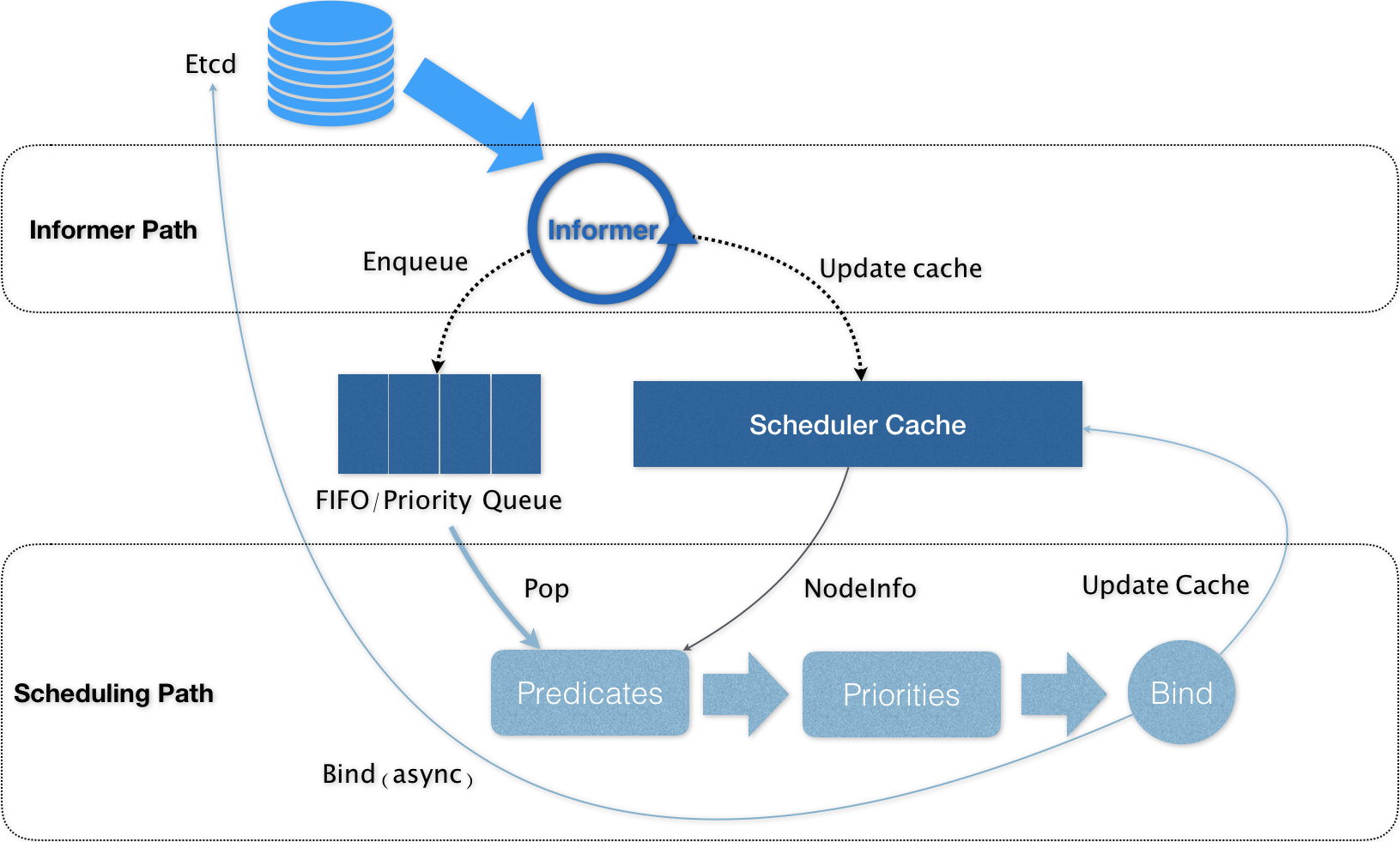
k8s-scheduler control path
Informer Path
- 启动一系列 Informer,用来监听(Watch)Etcd 中 Pod、Node、Service 等与调度相关的 API 对象的变化。比如,当一个待调度 Pod(即:它的 nodeName 字段是空的)被创建出来之后,调度器就会通过 Pod Informer 的 Handler,将这个待调度 Pod 添加进调度队列
- Kubernetes 的调度队列是一个 PriorityQueue(优先级队列)
Scheduling Path
Scheduling Path 的主要逻辑,就是不断地从调度队列里出队一个 Pod。然后,调用 Predicates 算法进行“过滤”。这一步“过滤”得到的一组 Node,就是所有可以运行这个 Pod 的宿主机列表。
k8s-scheduler 调度过程
Predicate
从集群所有的节点中,根据调度算法挑选出所有可以运行该 Pod 的节点;
Priority
从第一步的结果中,再根据调度算法挑选一个最符合条件的节点作为最终结果。
调度特性
- 在 Scheduling Path 上,调度器会启动多个 Goroutine 以节点为粒度并发执行 Predicates 算法,从而提高这一阶段的执行效率。而与之类似的,Priorities 算法也会以 MapReduce 的方式并行计算然后再进行汇总。而在这些所有需要并发的路径上,调度器会避免设置任何全局的竞争资源,从而免去了使用锁进行同步带来的巨大的性能损耗
- 算法执行完成后,调度器就需要将 Pod 对象的 nodeName 字段的值,修改为上述 Node 的名字。这个步骤在 Kubernetes 里面被称作 Bind。
- Kubernetes 的默认调度器在 Bind 阶段,只会更新 Scheduler Cache 里的 Pod 和 Node 的信息。这种基于“乐观”假设的 API 对象更新方式,在 Kubernetes 里被称作 Assume
- Assume 之后,调度器才会创建一个 Goroutine 来异步地向 APIServer 发起更新 Pod 的请求,来真正完成 Bind 操作。如果这次异步的 Bind 过程失败了,其实也没有太大关系,等 Scheduler Cache 同步之后一切就会恢复正常
Scheduler Framework
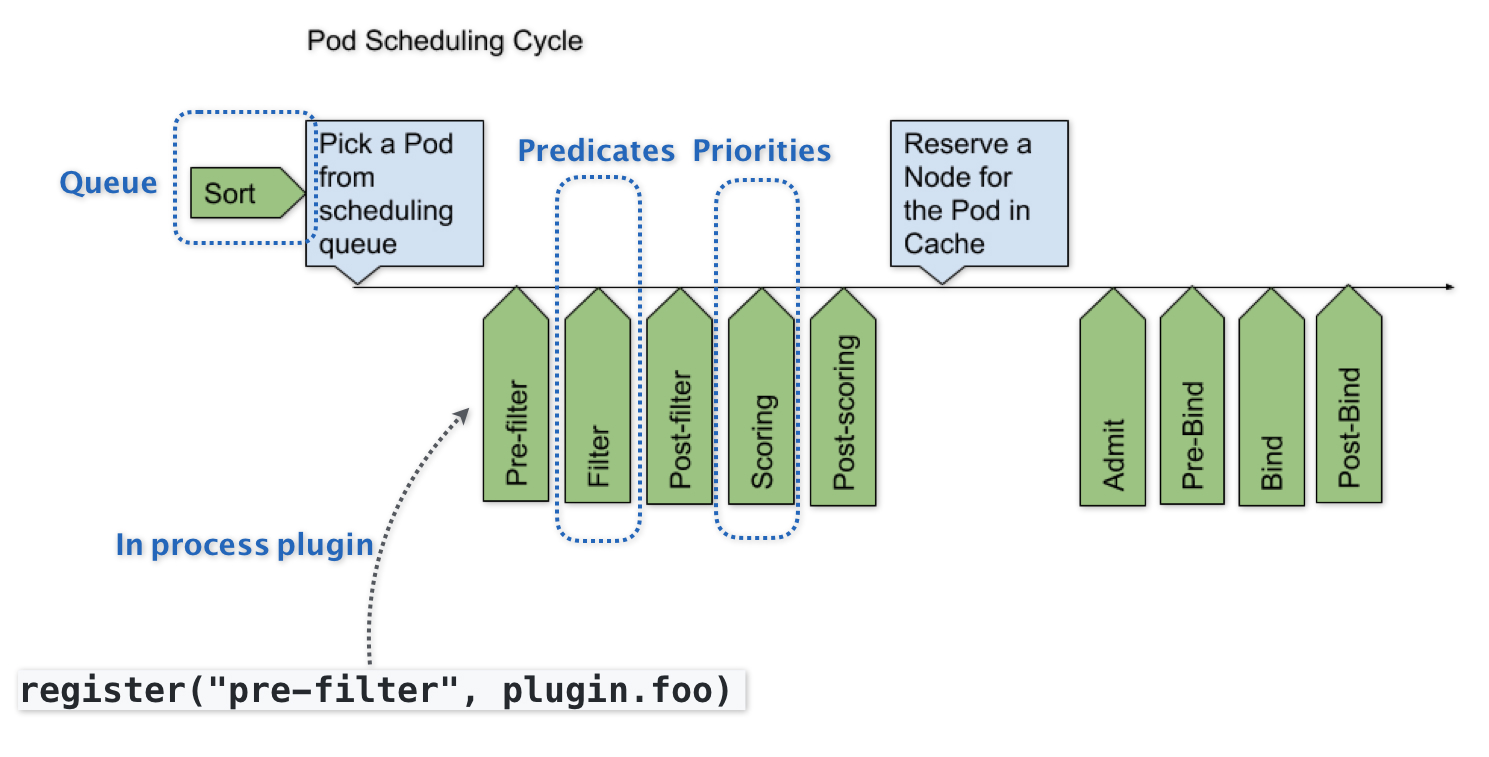
Kubernetes 默认调度器的可扩展性设计,每一个绿色的箭头都是一个可以插入自定义逻辑的接口
默认调度器调度策略解析
Predicate
在具体执行的时候, 当开始调度一个 Pod 时,Kubernetes 调度器会同时启动 16 个 Goroutine,来并发地为集群里的所有 Node 计算 Predicates,最后返回可以运行这个 Pod 的宿主机列表。
GeneralPredicates
资源限制类
- PodFitsResources:检查 CPU、内存资源是否足够
- PodFitsHostPorts:检查 hostPort 端口冲突
标签匹配类
- MatchNodeSelector:检查节点标签匹配
- CheckServiceAffinity:优化服务亲和性调度
节点状态类
- CheckNodeCondition:检查节点就绪状态
- CheckNodeLabelPresence:检查节点必须标签
污点容忍类
- PodToleratesNodeTaints:检查污点容忍
卷相关类
- CheckVolumeBinding:检查存储卷的绑定模式是否与 Pod 的请求相匹配。
- NoDiskConflict:检查已经挂载的卷不会与 Pod 申请的卷存在冲突。
- MaxEBSVolumeCount:检查节点上可挂载的最大 EBS 卷数量。
- MaxGCEPDVolumeCount:检查节点可挂载的最大 GCE PD 卷数量。
- MaxAzureDiskVolumeCount:检查节点上可用的 Azure 磁盘数量。
- MaxCSIVolumeCountPred:检查节点上可挂载的最大 CSI 卷数量。
- NoVolumeZoneConflict:检查请求的卷不会与拓扑域的限制冲突
Priority
在 Predicates 阶段完成了节点的“过滤”之后,Priorities 阶段的工作就是为这些节点打分。
Priorities分类
常见的默认 Priorities 包含:
- LeastRequestedPriority:得分基于节点上已请求的资源量,请求越少得分越高。
- BalancedResourceAllocation:优化 CPU 和内存使用率,避免析构。
- ServiceSpreadingPriority:尽量均匀分布服务的 Pod。
- EqualPriority:所有节点优先级相同。
- ImageLocalityPriority:倾向于已经具有镜像的节点。
- NodeAffinityPriority:优先匹配节点亲和性的节点。
- NodePreferAvoidPodsPriority:倾向于避开包含特定 pod 的节点。
- TaintTolerationPriority:优先 Toleration 匹配 Node 的 taint。
- InterPodAffinityPriority:优先匹配 Pod 亲和性的节点
LeastRequestedPriority
得分基于节点上已请求的资源量,请求越少得分越高
score = (cpu((capacity-sum(requested))10/capacity) + memory((capacity-sum(requested))10/capacity))/2
apiVersion: v1
kind: Pod
spec:
priorityClassName: system-cluster-critical
// 通过设置 priorityClassName 为系统集群关键类,可以使用 LeastRequestedPriority,把 Pod 调度到请求资源少的节点。
BalancedResourceAllocation
优化 CPU 和内存使用率,避免析构
apiVersion: v1
kind: Pod
spec:
priorityClassName: balanced-resource
ServiceSpreadingPriority
尽量均匀分布服务的 Pod
apiVersion: v1
kind: Pod
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- store
topologyKey: kubernetes.io/hostname
// 这里使用 podAntiAffinity 让具有 app=store 标签的 Pod 尽量分布到各个节点上。
NodeAffinityPriority
apiVersion: v1
kind: Pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu
operator: Exists
//这里使用 nodeAffinity 让 Pod 优先调度到有 GPU 的节点上。
优先级与抢占机制
优先级(Priority )
优先级机制用于给不同的 Pod 分配一个权重,以确定哪些 Pod 更重要,应该更优先地被调度。默认调度器使用优先级来对节点上的所有 Pod 进行排序,从而决定哪些 Pod 可以首先获得可用资源并被调度。
- Pod 可以通过设置
spec.priorityClassName字段来定义自己的优先级。每个priorityClassName都对应一个优先级值,这些值可以配置在 kube-scheduler 的配置文件中。默认情况下,Kubernetes 预定义了几个优先级类,例如 system-node-critical、system-cluster-critical 等,它们用于标记重要的系统 Pod。 - 优先级机制不是强制性的,如果 Pod 没有指定
priorityClassName,它将被赋予默认的优先级。 - PriorityClass 和Pod使用 priority class例子
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods only."
apiVersion: v1
kind: Pod
metadata:
name: nginx
labels:
env: test
spec:
containers:
- name: nginx
image: nginx
imagePullPolicy: IfNotPresent
priorityClassName: high-priority
抢占(Preemption)
抢占机制
抢占机制允许 Kubernetes 在节点资源不足时,通过驱逐较低优先级的 Pod 来为优先级更高的 Pod 腾出资源。
- 节点资源不足时,kube-scheduler 将按照优先级从高到低的顺序检查 Pod,直到找到可以驱逐的低优先级 Pod 来释放资源。被驱逐的 Pod 将会被重新调度到其他节点上。
- 抢占机制通过 kube-scheduler 自动完成,无需用户手动干预。但需要注意的是,某些 Pod 可能会被标记为不可抢占,以防止它们在资源不足时被驱逐。
- 当抢占过程发生时,抢占者并不会立刻被调度到被抢占的 Node 上。事实上,调度器只会将抢占者的 spec.nominatedNodeName 字段,设置为被抢占的 Node 的名字。然后,抢占者会重新进入下一个调度周期,然后在新的调度周期里来决定是不是要运行在被抢占的节点上。这当然也就意味着,即使在下一个调度周期,调度器也不会保证抢占者一定会运行在被抢占的节点上
- 鉴于优雅退出期间,集群的可调度性可能会发生的变化,把抢占者交给下一个调度周期再处理,是一个非常合理的选择
Kubernetes 抢占调度流程
执行流程
- 当一个Pod被标记为抢占(preemption)时,调度器会为其查找符合条件的牺牲Pod。
- 调度器会根据优先级、资源请求、调度器配置等条件来选择牺牲Pod。
- 其中,优先级最低的Pod最有可能被选为牺牲Pod。此外,资源请求越大的Pod被抢占的可能性也越大。
- 在找到可行的牺牲Pod后,调度器会发出抢占动作,回收牺牲Pod所在Node上的对应资源。
- 被抢占的牺牲Pod会被删除或驱逐,释放节点资源。
- 释放出的资源会为抢占Pod提供运行所需的资源,从而实现抢占Pod的调度。
- 在抢占过程中,调度器会尽量确保服务质量,最小化对EXISTING工作负载的影响。
- 如果在合理时间内无法找到合适的牺牲Pod,则抢占操作会被取消