Kubernetes GPU管理探秘第二篇:在Kubernetes中启用 Nvidia MPS
背景介绍
多进程服务(Multi-Process Service,MPS)是一个与CUDA API二进制兼容的客户端-服务器运行时实现,它由几个组件构成:
- 控制守护进程:负责启动和停止服务器,并协调客户端与服务器之间的连接。
- 客户端运行时:集成在CUDA驱动库中的MPS客户端运行时,可被任何CUDA应用程序透明地使用。
- 服务器进程:作为客户端共享访问GPU的桥梁,提供客户端间的并发。 本文档将介绍Volta MPS相较于前Volta GPU上的MPS的新功能,并指出两者之间的差异。在Volta上运行MPS会自动启用新功能。
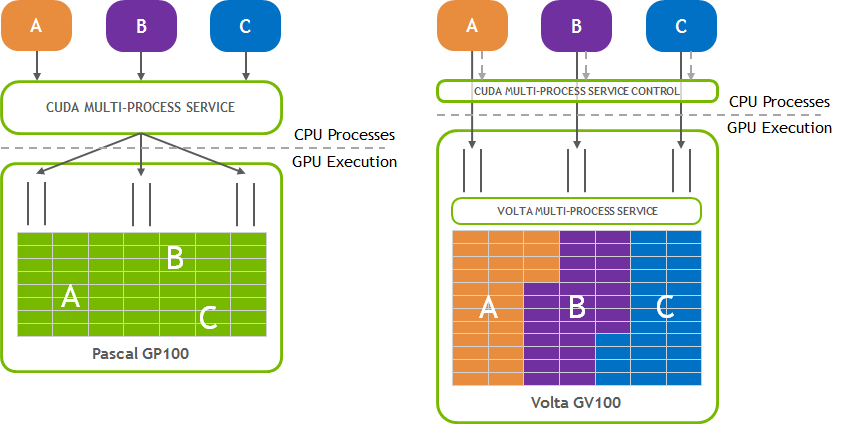
在K8s中使用NVIDIA MPS
根据来自NVIDIA GPU Device Plugin v0.15.0的说明,这个MPS功能还没有准备好用于生产环境,并包括一些已知问题,包括:
- device plugin可能在准备好分配共享GPU之前就显示为已启动,同时等待CUDA MPS控制守护进程上线。
- 在重启或配置更改下,CUDA MPS控制守护进程和GPU device plugin之间没有同步。这意味着,如果工作负载在失去对由CUDA MPS控制守护进程控制的共享资源的访问时可能会崩溃。
- MPS仅支持完整的GPU。
- 不可能“组合”MPS GPU请求,以允许单个容器访问更多内存。
本文将对该功能进行验证,以便在未来的版本中使用。
环境准备
k8s集群信息
- Kernel Version: 5.15.135-amd64
- containerd version 1.6.20
- Kubelet Version: v1.26.11
- k8s-device-plugin version: v0.15.0
- nvidia-toolkit upgrade: v1.13.4
安装 Nvidia GPU Operator
首先,我们需要安装Nvidia GPU Operator,以提供GPU资源的监控指标。
helm install --wait --generate-name -n ssdl-vgpu nvidia/gpu-operator \
--set driver.enabled=false \
--set toolkit.enabled=false \
--set devicePlugin.enabled=false
准备MPS对应的configMap
# k apply -f ntr-mps-cm.yaml
```yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: ntr-mps-cm
namespace: ssdl-vgpu
data:
any: |
version: v1
flags:
failOnInitError: true
nvidiaDriverRoot: "/run/nvidia/driver/"
plugin:
deviceListStrategy: envvar
deviceIDStrategy: uuid
sharing:
mps:
resources:
- name: nvidia.com/gpu
replicas: 4
安装 nvidia-device-plugin
helm install --wait k8s-vgpu nvdp/nvidia-device-plugin \
--namespace ssdl-vgpu \
--version 0.15.0 \
--set config.name=ntr-time-cm \
--set compatWithCPUManager=true \
helm list -n ssdl-vgpu | grep k8s-vgpu
k8s-vgpu ssdl-vgpu 3 2024-04-23 14:04:36.885665 +0800 CST deployed nvidia-device-plugin-0.15.0 0.15.0
在nvidia-device-plugin安装完成后,我们可以查看DaemonSet的状态。
k get DaemonSet -n ssdl-vgpu | grep k8s-vgpu
k8s-vgpu-nvidia-device-plugin 1 1 1 1 1 <none> 6h36m
k8s-vgpu-nvidia-device-plugin-mps-control-daemon 1 1 1 1 1 nvidia.com/mps.capable=true 6h36m
标记目标node以启用MPS
基于上面的输出,我们可以看到DaemonSet k8s-vgpu-nvidia-device-plugin-mps-control-daemon正在运行。我们可以标记目标node以启用MPS。
k label no -l worker.garden.sapcloud.io/group=c32m384-v100g3 nvidia.com/mps.capable=true
结果验证
MPS control daemon and device-plugin的日志
MPS control daemon logs
2024-04-23T06:04:59.093748766Z I0423 06:04:59.092447 55 main.go:78] Starting NVIDIA MPS Control Daemon 435bfb70
2024-04-23T06:04:59.093839331Z commit: 435bfb70a44b74daca23fe957a0f256afaa3c51e
2024-04-23T06:04:59.093853836Z I0423 06:04:59.092736 55 main.go:55] "Starting NVIDIA MPS Control Daemon" version=<
2024-04-23T06:04:59.093867206Z 435bfb70
2024-04-23T06:04:59.093878874Z commit: 435bfb70a44b74daca23fe957a0f256afaa3c51e
2024-04-23T06:04:59.093889630Z >
2024-04-23T06:04:59.093900576Z I0423 06:04:59.092874 55 main.go:107] Starting OS watcher.
2024-04-23T06:04:59.094030621Z I0423 06:04:59.093463 55 main.go:121] Starting Daemons.
2024-04-23T06:04:59.094062157Z I0423 06:04:59.093551 55 main.go:164] Loading configuration.
2024-04-23T06:04:59.094686515Z I0423 06:04:59.094616 55 main.go:172] Updating config with default resource matching patterns.
2024-04-23T06:04:59.094774486Z I0423 06:04:59.094718 55 main.go:183]
2024-04-23T06:04:59.094792480Z Running with config:
2024-04-23T06:04:59.094796229Z {
2024-04-23T06:04:59.094799702Z "version": "v1",
2024-04-23T06:04:59.094802996Z "flags": {
2024-04-23T06:04:59.094806479Z "migStrategy": "none",
2024-04-23T06:04:59.094809741Z "failOnInitError": true,
2024-04-23T06:04:59.094813226Z "nvidiaDriverRoot": "/run/nvidia/driver/",
2024-04-23T06:04:59.094816715Z "gdsEnabled": null,
2024-04-23T06:04:59.094820702Z "mofedEnabled": null,
2024-04-23T06:04:59.094823952Z "useNodeFeatureAPI": null,
2024-04-23T06:04:59.094827235Z "plugin": {
2024-04-23T06:04:59.094830383Z "passDeviceSpecs": null,
2024-04-23T06:04:59.094833529Z "deviceListStrategy": [
2024-04-23T06:04:59.094836708Z "envvar"
2024-04-23T06:04:59.094840338Z ],
2024-04-23T06:04:59.094844148Z "deviceIDStrategy": "uuid",
2024-04-23T06:04:59.094847589Z "cdiAnnotationPrefix": null,
2024-04-23T06:04:59.094850905Z "nvidiaCTKPath": null,
2024-04-23T06:04:59.094854382Z "containerDriverRoot": null
2024-04-23T06:04:59.094857781Z }
2024-04-23T06:04:59.094861393Z },
2024-04-23T06:04:59.094870585Z "resources": {
2024-04-23T06:04:59.094873870Z "gpus": [
2024-04-23T06:04:59.094877070Z {
2024-04-23T06:04:59.094882321Z "pattern": "*",
2024-04-23T06:04:59.094885531Z "name": "nvidia.com/gpu"
2024-04-23T06:04:59.094888738Z }
2024-04-23T06:04:59.094891938Z ]
2024-04-23T06:04:59.094895130Z },
2024-04-23T06:04:59.094898375Z "sharing": {
2024-04-23T06:04:59.094901556Z "timeSlicing": {},
2024-04-23T06:04:59.094904765Z "mps": {
2024-04-23T06:04:59.094908027Z "failRequestsGreaterThanOne": true,
2024-04-23T06:04:59.094911202Z "resources": [
2024-04-23T06:04:59.094914378Z {
2024-04-23T06:04:59.094917668Z "name": "nvidia.com/gpu",
2024-04-23T06:04:59.094920946Z "devices": "all",
2024-04-23T06:04:59.094924462Z "replicas": 4
2024-04-23T06:04:59.094927756Z }
2024-04-23T06:04:59.094931025Z ]
2024-04-23T06:04:59.094934399Z }
2024-04-23T06:04:59.094937659Z }
2024-04-23T06:04:59.094940881Z }
2024-04-23T06:04:59.094944445Z I0423 06:04:59.094737 55 main.go:187] Retrieving MPS daemons.
2024-04-23T06:04:59.367188348Z I0423 06:04:59.366922 55 daemon.go:93] "Staring MPS daemon" resource="nvidia.com/gpu"
2024-04-23T06:04:59.443650558Z I0423 06:04:59.443468 55 daemon.go:131] "Starting log tailer" resource="nvidia.com/gpu"
2024-04-23T06:04:59.445568425Z [2024-04-23 06:04:59.389 Control 72] Starting control daemon using socket /mps/nvidia.com/gpu/pipe/control
2024-04-23T06:04:59.445618049Z [2024-04-23 06:04:59.389 Control 72] To connect CUDA applications to this daemon, set env CUDA_MPS_PIPE_DIRECTORY=/mps/nvidia.com/gpu/pipe
2024-04-23T06:04:59.445627888Z [2024-04-23 06:04:59.415 Control 72] Accepting connection...
2024-04-23T06:04:59.445635791Z [2024-04-23 06:04:59.415 Control 72] NEW UI
2024-04-23T06:04:59.445643954Z [2024-04-23 06:04:59.415 Control 72] Cmd:set_default_device_pinned_mem_limit 0 4096M
2024-04-23T06:04:59.445651895Z [2024-04-23 06:04:59.415 Control 72] UI closed
2024-04-23T06:04:59.445659400Z [2024-04-23 06:04:59.418 Control 72] Accepting connection...
2024-04-23T06:04:59.445667180Z [2024-04-23 06:04:59.418 Control 72] NEW UI
2024-04-23T06:04:59.445674877Z [2024-04-23 06:04:59.418 Control 72] Cmd:set_default_device_pinned_mem_limit 1 4096M
2024-04-23T06:04:59.445682790Z [2024-04-23 06:04:59.419 Control 72] UI closed
2024-04-23T06:04:59.445690190Z [2024-04-23 06:04:59.439 Control 72] Accepting connection...
2024-04-23T06:04:59.445697598Z [2024-04-23 06:04:59.439 Control 72] NEW UI
2024-04-23T06:04:59.445705544Z [2024-04-23 06:04:59.439 Control 72] Cmd:set_default_device_pinned_mem_limit 2 4096M
2024-04-23T06:04:59.445713416Z [2024-04-23 06:04:59.439 Control 72] UI closed
2024-04-23T06:04:59.445720849Z [2024-04-23 06:04:59.442 Control 72] Accepting connection...
2024-04-23T06:04:59.445728295Z [2024-04-23 06:04:59.442 Control 72] NEW UI
2024-04-23T06:04:59.445735742Z [2024-04-23 06:04:59.442 Control 72] Cmd:set_default_active_thread_percentage 25
2024-04-23T06:04:59.445749210Z [2024-04-23 06:04:59.442 Control 72] 25.0
2024-04-23T06:04:59.445757584Z [2024-04-23 06:04:59.442 Control 72] UI closed
2024-04-23T06:05:26.660115113Z [2024-04-23 06:05:26.659 Control 72] Accepting connection...
2024-04-23T06:05:26.660166122Z [2024-04-23 06:05:26.659 Control 72] NEW UI
2024-04-23T06:05:26.660179349Z [2024-04-23 06:05:26.659 Control 72] Cmd:get_default_active_thread_percentage
2024-04-23T06:05:26.660189426Z [2024-04-23 06:05:26.659 Control 72] 25.0
Nvidia-device-plugin logs
I0423 06:04:56.479370 39 main.go:279] Retrieving plugins.
I0423 06:04:56.480927 39 factory.go:104] Detected NVML platform: found NVML library
I0423 06:04:56.480999 39 factory.go:104] Detected non-Tegra platform: /sys/devices/soc0/family file not found
E0423 06:04:56.558122 39 main.go:301] Failed to start plugin: error waiting for MPS daemon: error checking MPS daemon health: failed to send command to MPS daemon: exit status 1
I0423 06:04:56.558152 39 main.go:208] Failed to start one or more plugins. Retrying in 30s...
I0423 06:05:26.587365 39 main.go:315] Stopping plugins.
I0423 06:05:26.587429 39 server.go:185] Stopping to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
I0423 06:05:26.587496 39 main.go:200] Starting Plugins.
I0423 06:05:26.587508 39 main.go:257] Loading configuration.
I0423 06:05:26.588327 39 main.go:265] Updating config with default resource matching patterns.
I0423 06:05:26.588460 39 main.go:276]
Running with config:
{
"version": "v1",
"flags": {
"migStrategy": "none",
"failOnInitError": true,
"mpsRoot": "/run/nvidia/mps",
"nvidiaDriverRoot": "/run/nvidia/driver/",
"gdsEnabled": false,
"mofedEnabled": false,
"useNodeFeatureAPI": null,
"plugin": {
"passDeviceSpecs": false,
"deviceListStrategy": [
"envvar"
],
"deviceIDStrategy": "uuid",
"cdiAnnotationPrefix": "cdi.k8s.io/",
"nvidiaCTKPath": "/usr/bin/nvidia-ctk",
"containerDriverRoot": "/driver-root"
}
},
"resources": {
"gpus": [
{
"pattern": "*",
"name": "nvidia.com/gpu"
}
]
},
"sharing": {
"timeSlicing": {},
"mps": {
"failRequestsGreaterThanOne": true,
"resources": [
{
"name": "nvidia.com/gpu",
"devices": "all",
"replicas": 4
}
]
}
}
}
I0423 06:05:26.588478 39 main.go:279] Retrieving plugins.
I0423 06:05:26.588515 39 factory.go:104] Detected NVML platform: found NVML library
I0423 06:05:26.588559 39 factory.go:104] Detected non-Tegra platform: /sys/devices/soc0/family file not found
I0423 06:05:26.660603 39 server.go:176] "MPS daemon is healthy" resource="nvidia.com/gpu"
I0423 06:05:26.661346 39 server.go:216] Starting GRPC server for 'nvidia.com/gpu'
I0423 06:05:26.662857 39 server.go:147] Starting to serve 'nvidia.com/gpu' on /var/lib/kubelet/device-plugins/nvidia-gpu.sock
I0423 06:05:26.673960 39 server.go:154] Registered device plugin for 'nvidia.com/gpu' with Kubelet
E2E 校验
✅成功的案例 -> cuda-samples/vectorAdd
cuda-samples 所对应的日志,从中我们可以看到 MPS已经成功地启用了。
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
nvidia-smi 对应的输出
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1127738 C nvidia-cuda-mps-server 30MiB |
| 0 N/A N/A 1397691 M+C /cuda-samples/vectorAdd 18MiB |
| 0 N/A N/A 1397696 M+C /cuda-samples/vectorAdd 10MiB |
| 1 N/A N/A 1127738 C nvidia-cuda-mps-server 30MiB |
| 1 N/A N/A 1397689 M+C /cuda-samples/vectorAdd 94MiB |
| 1 N/A N/A 1397714 M+C /cuda-samples/vectorAdd 10MiB |
| 2 N/A N/A 1127738 C nvidia-cuda-mps-server 30MiB |
| 2 N/A N/A 1397712 M+C /cuda-samples/vectorAdd 10MiB |
+---------------------------------------------------------------------------------------+
❌失败的案例 -> tf-notebook tensorflow/tensorflow:latest-gpu-jupyter
我在尝试使用这个classification.ipynb来进行端到端验证,然而结果是pod持续挂起60分钟没有任何响应,并且日志无法获取更多细节。
classification.ipynb的日志输出
2024-04-25 02:10:19.499819: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
[I 2024-04-25 02:10:20.630 ServerApp] Connecting to kernel 562db3f6-327c-4adc-83e9-735fb4d0042c.
[I 2024-04-25 02:10:36.700 ServerApp] Connecting to kernel 562db3f6-327c-4adc-83e9-735fb4d0042c.
我在此处尝试了echo get_default_active_thread_percentage | nvidia-cuda-mps-control(来自于https://github.com/NVIDIA/k8s-device-plugin/issues/647),一切看起来都很正常,但是挂起的问题仍然存在。
root@gpu-pod:/# echo get_default_active_thread_percentage | nvidia-cuda-mps-control
25.0
相关的 Github Issues
- Workloads keep in hang state except cuda-sample:vectoradd under MPS mode
- MPS use error: Failed to allocate device vector A (error code all CUDA-capable devices are busy or unavailable)!