Kubernetes GPU管理探秘第一篇:Kubernetes Device Plugin介绍和源码分析
k8s GPU device plugin介绍和源码分析
前言
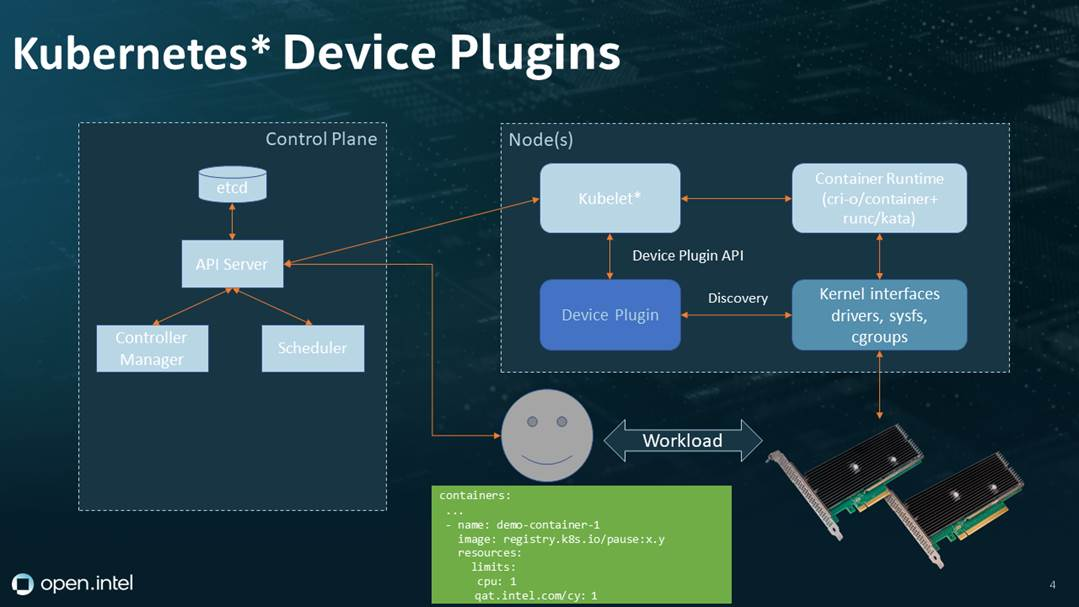
在 Kubernetes 集群中,有些工作负载需要访问节点上的硬件资源,比如 GPU、FPGA、InfiniBand 等。为了让 Kubernetes 能够感知和调度这些硬件资源,Kubernetes 引入了 Device Plugin 的概念。本文将详细介绍 Device Plugin 的工作原理。
Device Plugin 简介
Device Plugin 是 Kubernetes 中一种特殊的插件,负责管理节点上的硬件设备,并将设备信息呈现给 Kubernetes。每种类型的硬件设备,都需要有它对应的 Device Plugin 进程在运行。通常,这些 Device Plugin 进程是由硬件供应商提供的。
Device Plugin 通过 gRPC 服务与 kubelet 进行通信,履行了以下两个主要职责:
- 发现节点上的硬件设备
- 准备并安装需要使用设备的容器运行时环境
Device Plugin 工作流程
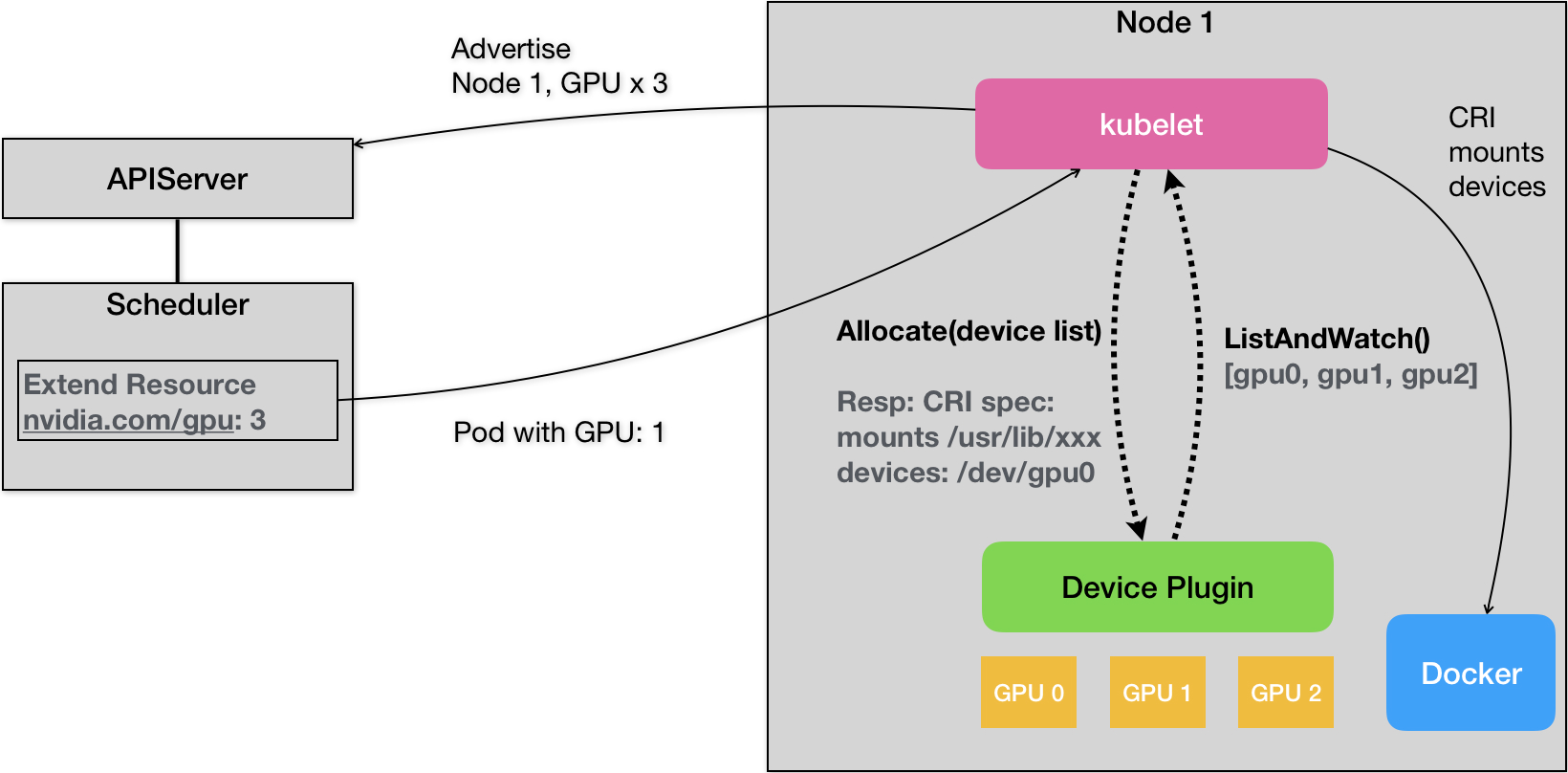
下面让我们通过一个具体的例子,来了解 Device Plugin 的工作流程。假设有一个节点上安装了 3 块 NVIDIA GPU 设备,现在要让一个 Pod 使用其中一块 GPU 设备。
设备发现
在节点启动时,kubelet 首先启动该节点上的所有 Device Plugin。以 NVIDIA GPU 设备为例,kubelet 会启动 nvidia-device-plugin 进程。
该 Device Plugin 通过 gRPC 的 ListAndWatch 远程过程调用,定期向 kubelet 汇报该节点上可用的 GPU 设备列表。在我们的例子中,就是 [GPU0, GPU1, GPU2] 这个 ID 列表。注意,这个列表只包含 GPU 设备的 ID,不包括任何关于设备本身的详细信息。kubelet 将这些设备 ID 保存在内存中,并通过 API Server 将 GPU 的数量以 Extended Resource 的形式暴露出去。
调度决策
当用户想要创建一个使用 GPU 的 Pod 时,只需在 Pod 声明中添加 limits 小节,指定所需的 GPU 数量即可,就像下面这样:
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "k8s.gcr.io/cuda-vector-add:v0.1"
resources:
limits:
nvidia.com/gpu: 1 # 请求1个GPU
此时,Kubernetes 调度器会查找有足够 GPU 资源的节点来运行该 Pod。调度器从 API Server 获取节点的 GPU 资源数量,找到符合条件的节点后,将该节点的 GPU 资源数量减1,完成 Pod 到节点的绑定。
设备分配
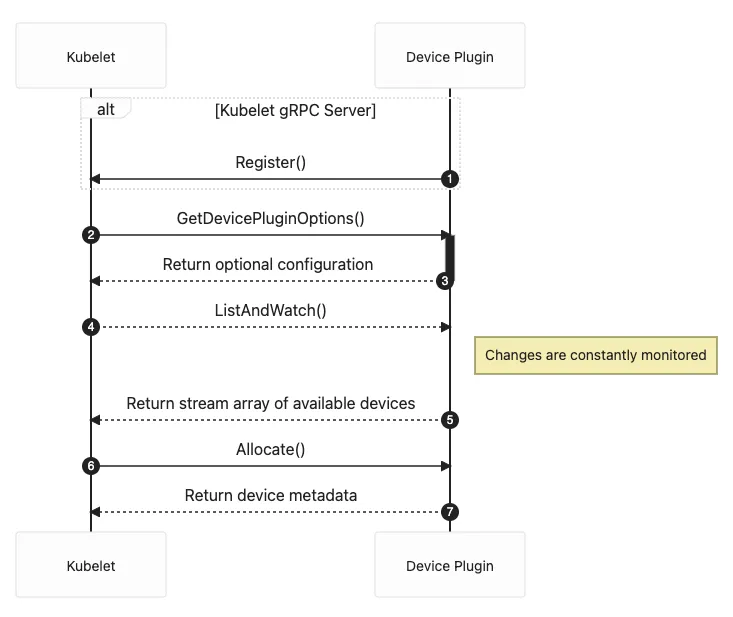
一旦某个节点被选中运行 GPU Pod,该节点上的 kubelet 就会为 Pod 中的容器分配实际的 GPU 设备。kubelet 会向本节点上的 nvidia-device-plugin 发送 gRPC Allocate 请求,指定需要分配的 GPU 设备 ID 列表。
nvidia-device-plugin 根据接收到的 GPU ID 列表,查找对应设备的更多信息,比如设备文件路径、驱动文件目录等。这些信息会随 gRPC 响应一并返回给 kubelet。
在 kubelet 中,处理 GPU 请求和分配会涉及以下的代码:
if pod.Spec.Containers[0].Resources.Limits["nvidia.com/gpu"] == 1 {
// 搜索可用设备
deviceIDs, err := findAvailableGPUs()
if err != nil {
// 处理错误
}
// 向设备插件发送 Allocate 请求
_, err = devicePluginClient.Allocate(context.TODO(), &pluginapi.AllocateRequest{ContainerRequests: []*pluginapi.ContainerAllocateRequest{{DevicesIDs: deviceIDs}}})
if err != nil {
// 处理错误
}
}
容器启动
kubelet 收到 nvidia-device-plugin 返回的 GPU 设备信息后,就可以为 Pod 中的容器创建正确的运行环境了。它将设备文件路径作为容器的 Devices 参数,驱动文件目录作为容器的 Volume Mounts 参数,传递给容器运行时(如 Docker)。
容器运行时根据这些参数启动容器,并完成设备资源的挂载,最终使 Pod 中的应用可以访问分配的 GPU 设备。
源码分析
本文以https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/cm/devicemanager/manager.go此处的源代码进行分析。
Kubernetes 使用设备插件来进行设备管理,包括GPU设备。设备插件允许第三方资源如 GPU 被 Kubernetes 识别和管理。 这个机制的核心部分是 ManagerImpl,这是由 Kubernetes 编写并运行在 Kubelet 中的。
- 结构体
ManagerImpl管理设备插件。它存储设备插件的各类信息,其中endpoints用于存放设备插件的 endpoint 信息,每一个 endpoint 代表了一个设备插件接口。healthyDevices中存储的是所有健康的设备资源名和设备 ID。unhealthyDevices是一个设备名到设备ID集合的映射,存储的是所有处于非健康状态的设备。allocatedDevices是一个设备名到设备ID集合的映射,它存储的是所有已经被分配出去(正在使用)的设备。
type ManagerImpl struct {
checkpointdir string
endpoints map[string]endpointInfo // Key is ResourceName
mutex sync.Mutex
server plugin.Server
// activePods is a method for listing active pods on the node
// so the amount of pluginResources requested by existing pods
// could be counted when updating allocated devices
activePods ActivePodsFunc
// sourcesReady provides the readiness of kubelet configuration sources such as apiserver update readiness.
// We use it to determine when we can purge inactive pods from checkpointed state.
sourcesReady config.SourcesReady
// allDevices holds all the devices currently registered to the device manager
allDevices ResourceDeviceInstances
// healthyDevices contains all the registered healthy resourceNames and their exported device IDs.
healthyDevices map[string]sets.Set[string]
// unhealthyDevices contains all the unhealthy devices and their exported device IDs.
unhealthyDevices map[string]sets.Set[string]
// allocatedDevices contains allocated deviceIds, keyed by resourceName.
allocatedDevices map[string]sets.Set[string]
// podDevices contains pod to allocated device mapping.
podDevices *podDevices
checkpointManager checkpointmanager.CheckpointManager
// List of NUMA Nodes available on the underlying machine
numaNodes []int
// Store of Topology Affinities that the Device Manager can query.
topologyAffinityStore topologymanager.Store
// devicesToReuse contains devices that can be reused as they have been allocated to
// init containers.
devicesToReuse PodReusableDevices
// pendingAdmissionPod contain the pod during the admission phase
pendingAdmissionPod *v1.Pod
// containerMap provides a mapping from (pod, container) -> containerID
// for all containers in a pod. Used to detect pods running across a restart
containerMap containermap.ContainerMap
// containerRunningSet identifies which container among those present in `containerMap`
// was reported running by the container runtime when `containerMap` was computed.
// Used to detect pods running across a restart
containerRunningSet sets.Set[string]
}
- 方法
Allocate: 当Pod请求使用某种设备插件(如GPU)的设备资源时,会调用这个方法 。方法会根据container.Resources.Limits来获取每种设备资源需要请求的数量,然后为每个设备资源类型调用devicesToAllocate方法,该方法会返回需要经过 Allocate 请求来分配的设备列表。然后对于每种设备资源,会调用allocateContainerResources方法,该方法会首先尝试从对应设备的健康设备集合中分配设备,然后更新podDevices状态并发起 Allocate 请求,失败的话则回滚。
func (m *ManagerImpl) Allocate(pod *v1.Pod, container *v1.Container) error {
// The pod is during the admission phase. We need to save the pod to avoid it
// being cleaned before the admission ended
m.setPodPendingAdmission(pod)
if _, ok := m.devicesToReuse[string(pod.UID)]; !ok {
m.devicesToReuse[string(pod.UID)] = make(map[string]sets.Set[string])
}
// If pod entries to m.devicesToReuse other than the current pod exist, delete them.
for podUID := range m.devicesToReuse {
if podUID != string(pod.UID) {
delete(m.devicesToReuse, podUID)
}
}
// Allocate resources for init containers first as we know the caller always loops
// through init containers before looping through app containers. Should the caller
// ever change those semantics, this logic will need to be amended.
for _, initContainer := range pod.Spec.InitContainers {
if container.Name == initContainer.Name {
if err := m.allocateContainerResources(pod, container, m.devicesToReuse[string(pod.UID)]); err != nil {
return err
}
if !types.IsRestartableInitContainer(&initContainer) {
m.podDevices.addContainerAllocatedResources(string(pod.UID), container.Name, m.devicesToReuse[string(pod.UID)])
} else {
// If the init container is restartable, we need to keep the
// devices allocated. In other words, we should remove them
// from the devicesToReuse.
m.podDevices.removeContainerAllocatedResources(string(pod.UID), container.Name, m.devicesToReuse[string(pod.UID)])
}
return nil
}
}
if err := m.allocateContainerResources(pod, container, m.devicesToReuse[string(pod.UID)]); err != nil {
return err
}
m.podDevices.removeContainerAllocatedResources(string(pod.UID), container.Name, m.devicesToReuse[string(pod.UID)])
return nil
}
- 方法
GetCapacity: 该方法被 Kubelet 调用,以获取设备的容量信息,用于在 Node 对象中报告 Node 的设备资源情况,其中包含容量(未分配设备)、可分配(未分配并且健康状态)和已经丢失(已停止或者健康状态变为非健康)的设备列表。如果设备插件处于非健康状态,则删除容量和 device plugin 的资源映射。
func (m *ManagerImpl) GetCapacity() (v1.ResourceList, v1.ResourceList, []string) {
needsUpdateCheckpoint := false
var capacity = v1.ResourceList{}
var allocatable = v1.ResourceList{}
deletedResources := sets.New[string]()
m.mutex.Lock()
for resourceName, devices := range m.healthyDevices {
eI, ok := m.endpoints[resourceName]
if (ok && eI.e.stopGracePeriodExpired()) || !ok {
// The resources contained in endpoints and (un)healthyDevices
// should always be consistent. Otherwise, we run with the risk
// of failing to garbage collect non-existing resources or devices.
if !ok {
klog.ErrorS(nil, "Unexpected: healthyDevices and endpoints are out of sync")
}
delete(m.endpoints, resourceName)
delete(m.healthyDevices, resourceName)
deletedResources.Insert(resourceName)
needsUpdateCheckpoint = true
} else {
capacity[v1.ResourceName(resourceName)] = *resource.NewQuantity(int64(devices.Len()), resource.DecimalSI)
allocatable[v1.ResourceName(resourceName)] = *resource.NewQuantity(int64(devices.Len()), resource.DecimalSI)
}
}
for resourceName, devices := range m.unhealthyDevices {
eI, ok := m.endpoints[resourceName]
if (ok && eI.e.stopGracePeriodExpired()) || !ok {
if !ok {
klog.ErrorS(nil, "Unexpected: unhealthyDevices and endpoints are out of sync")
}
delete(m.endpoints, resourceName)
delete(m.unhealthyDevices, resourceName)
deletedResources.Insert(resourceName)
needsUpdateCheckpoint = true
} else {
capacityCount := capacity[v1.ResourceName(resourceName)]
unhealthyCount := *resource.NewQuantity(int64(devices.Len()), resource.DecimalSI)
capacityCount.Add(unhealthyCount)
capacity[v1.ResourceName(resourceName)] = capacityCount
}
}
m.mutex.Unlock()
if needsUpdateCheckpoint {
if err := m.writeCheckpoint(); err != nil {
klog.ErrorS(err, "Error on writing checkpoint")
}
}
return capacity, allocatable, deletedResources.UnsortedList()
}
整个 ManagerImpl 的设计提供了对设备插件的抽象,使得 kubernetes 可以进行设备的管理和调度,并且允许设备插件的运行和设备状态发生变化(如设备丢失或者插件进程重启)
小结
通过上面的分析,我们了解了 Device Plugin 在 Kubernetes 中扮演了硬件设备的"转换器"角色:
- 将节点上的硬件设备信息转换为 Extended Resource,供调度器调度使用
- 将容器对硬件设备的请求转换为实际的设备文件和驱动目录,传递给容器运行时
这种插件化设计,使得 Kubernetes 具备了良好的硬件资源支持能力。无论是现有的还是新出现的硬件设备,只要提供了对应的 Device Plugin,就可以被 Kubernetes 集群所感知和利用。
通过本文,相信您对 Kubernetes Device Plugin 的工作原理有了更深入的理解。如果还有任何疑问,欢迎留言讨论。
参考链接
- https://techmythos.substack.com/p/a-beginners-guide-to-building-a-kubernetes
- https://kubernetes.io/blog/2022/12/19/devicemanager-ga/
- https://www.intel.com/content/www/us/en/developer/articles/technical/device-plugins-path-faster-workloads-in-kubernetes.html
- https://artifacts.opnfv.org/ra2/jenkins-cntt-tox-ra2-1376/chapters/chapter03.html
- https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/