掌握 Golang 的 sync.Map 并发安全容器
The new kid in town — Go’s sync.Map 的中文翻译版本,内容有删减。
本文是一个使用在 sync.Map 包中内置 map 的例子,
下面代码中的 RegularIntMap 采用了由 RWMutex构成的内置map
package RegularIntMap
type RegularIntMap struct {
sync.RWMutex
internal map[int]int
}
func NewRegularIntMap() *RegularIntMap {
return &RegularIntMap{
internal: make(map[int]int),
}
}
func (rm *RegularIntMap) Load(key int) (value int, ok bool) {
rm.RLock()
result, ok := rm.internal[key]
rm.RUnlock()
return result, ok
}
func (rm *RegularIntMap) Delete(key int) {
rm.Lock()
delete(rm.internal, key)
rm.Unlock()
}
func (rm *RegularIntMap) Store(key, value int) {
rm.Lock()
rm.internal[key] = value
rm.Unlock()
}
在上面的代码中,Load 是唯一不会改变内部映射状态的接收器方法。 这很重要,因为 Load 可以自由地获取读锁,为正在执行此方法的那些 goroutines 提供并发进度。
直到对标准库进行额外的审查和性能分析后,Go 团队的各个成员才发现,当在多核系统中使用sync.RWMutex时,性能并不理想。这里指的并不是 8 核或 16 核设置,而是那些远远超出此范围的服务器设置。此时内核数量真正开始以高度争议的代码形式显示的地方,在此时使用sync.RWMutex。
现在我们已经了解了为什么要创建 sync.Map。 Go 团队发现了标准库中性能不佳的情况。在某些情况下,项目是从sync.RWMutex中的数据结构中获取的,在高读取场景下,如果项目此时恰巧部署在多核服务器上,性能会受到很大影响。
事实上,在 2017 GopherCon 上,有一个关于它的精彩故事:An overview of sync.Map。 如果您正在考虑使用该实现,请观看此演讲,因为它可能存在一些性能陷阱。 此外,这次简短的演讲肯定会更深入地说明为什么要创建它以及它的设计目的。
让我们来看看下面的代码中查看sync.Map的用法:
func syncMapUsage() {
fmt.Println("sync.Map test (Go 1.9+ only)")
fmt.Println("----------------------------")
// Create the threadsafe map.
var sm sync.Map
// Fetch an item that doesn't exist yet.
result, ok := sm.Load("hello")
if ok {
fmt.Println(result.(string))
} else {
fmt.Println("value not found for key: `hello`")
}
// Store an item in the map.
sm.Store("hello", "world")
fmt.Println("added value: `world` for key: `hello`")
// Fetch the item we just stored.
result, ok = sm.Load("hello")
if ok {
fmt.Printf("result: `%s` found for key: `hello`\n", result.(string))
}
fmt.Println("---------------------------")
}
请注意,该 API 明显不同于常规的内置 map 用法。 此外,因为sync.Map的这种实现不是类型安全的, 当我们从sync.Map中获取(Load)项目时,所以我们必须进行类型转换,请注意此时可能会失败。
除了Load和Store,还有前面提到的Delete、LoadOrStore和最后Range的方法。可以参考golang的文档https://pkg.go.dev/sync#Map。
所以
sync.Map性能如何呢?
关于性能特征的文档如下所述:
它针对在并发循环进行了优化,键随时间稳定,以及少数稳态存储,或存储本地化到每个键在一个goroutine。
对于不共享这些属性的用例,与读写互斥锁配对的普通映射相比,它可能具有更差的性能和类型安全性。

第一个基准测试显示了使用 RWMutex 包装的常规内置 map 与 sync.Map 针对 Store 操作对比如何。
func nrand(n int) []int {
i := make([]int, n)
for ind := range i {
i[ind] = rand.Int()
}
return i
}
func BenchmarkStoreRegular(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
b.ResetTimer()
for _, v := range nums {
rm.Store(v, v)
}
}
func BenchmarkStoreSync(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
b.ResetTimer()
for _, v := range nums {
sm.Store(v, v)
}
}
/*
BenchmarkStoreRegular-32 5000000 319 ns/op
BenchmarkStoreSync-32 1000000 1146 ns/op
*/
接下来是关于 Delete 操作的基准测试。
func BenchmarkDeleteRegular(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
b.ResetTimer()
for _, v := range nums {
rm.Delete(v)
}
}
func BenchmarkDeleteSync(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
b.ResetTimer()
for _, v := range nums {
sm.Delete(v)
}
}
/*
BenchmarkDeleteRegular-32 10000000 238 ns/op
BenchmarkDeleteSync-32 5000000 393 ns/op
*/
接下来是关于 Load 操作的基准测试,其中 Found 的情况应该总是在映射中找到结果,而 NotFound 的情况将会几乎不会在map中找到结果。
func BenchmarkLoadRegularFound(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
currentResult, _ = rm.Load(nums[i])
}
globalResult = currentResult
}
func BenchmarkLoadRegularNotFound(b *testing.B) {
nums := nrand(b.N)
rm := NewRegularIntMap()
for _, v := range nums {
rm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
currentResult, _ = rm.Load(i)
}
globalResult = currentResult
}
func BenchmarkLoadSyncFound(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
r, ok := sm.Load(nums[i])
if ok {
currentResult = r.(int)
}
}
globalResult = currentResult
}
func BenchmarkLoadSyncNotFound(b *testing.B) {
nums := nrand(b.N)
var sm sync.Map
for _, v := range nums {
sm.Store(v, v)
}
currentResult := 0
b.ResetTimer()
for i := 0; i < b.N; i++ {
r, ok := sm.Load(i)
if ok {
currentResult = r.(int)
}
}
globalResult = currentResult
}
/*
BenchmarkLoadRegularFound-32 10000000 180 ns/op
BenchmarkLoadRegularNotFound-32 20000000 107 ns/op
BenchmarkLoadSyncFound-32 10000000 200 ns/op
BenchmarkLoadSyncNotFound-32 20000000 291 ns/op
*/
接下来是在多核中的基准测试,代码的主要部分将启动一个作为工作程序的 goroutine,它将通过使用 b.N 值进行尽可能多的迭代以满足 Go 的基准测试工具。对于每个运行中的 goroutine,我们将执行Load操作,并最终使用sync.WaitGroup发出信号,表明结束。
func benchmarkRegularStableKeys(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
rm := NewRegularIntMap()
populateMap(b.N, rm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
currentResult, _ = rm.Load(5)
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkSyncStableKeys(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
var sm sync.Map
populateSyncMap(b.N, &sm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
r, ok := sm.Load(5)
if ok {
currentResult = r.(int)
}
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkRegularStableKeysFound(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
rm := NewRegularIntMap()
values := populateMap(b.N, rm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
currentResult, _ = rm.Load(values[i])
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
func benchmarkSyncStableKeysFound(b *testing.B, workerCount int) {
runtime.GOMAXPROCS(workerCount)
var sm sync.Map
values := populateSyncMap(b.N, &sm)
var wg sync.WaitGroup
wg.Add(workerCount)
// Holds our final results, to prevent compiler optimizations.
globalResultChan = make(chan int, workerCount)
b.ResetTimer()
for wc := 0; wc < workerCount; wc++ {
go func(n int) {
currentResult := 0
for i := 0; i < n; i++ {
r, ok := sm.Load(values[i])
if ok {
currentResult = r.(int)
}
}
globalResultChan <- currentResult
wg.Done()
}(b.N)
}
wg.Wait()
}
/*
// These tests do a lookup using a literal value.
// Regular Map backed by RWMutex
BenchmarkRegularStableKeys1-32 50000000 30.5 ns/op
BenchmarkRegularStableKeys2-32 10000000 157 ns/op
BenchmarkRegularStableKeys4-32 5000000 377 ns/op
BenchmarkRegularStableKeys8-32 2000000 701 ns/op
BenchmarkRegularStableKeys16-32 1000000 1446 ns/op
BenchmarkRegularStableKeys32-32 500000 2825 ns/op
BenchmarkRegularStableKeys64-32 200000 5699 ns/op
// Sync Map
BenchmarkSyncStableKeys1-32 20000000 89.3 ns/op
BenchmarkSyncStableKeys2-32 20000000 101 ns/op
BenchmarkSyncStableKeys4-32 5000000 247 ns/op
BenchmarkSyncStableKeys8-32 5000000 330 ns/op
BenchmarkSyncStableKeys16-32 5000000 295 ns/op
BenchmarkSyncStableKeys32-32 5000000 269 ns/op
BenchmarkSyncStableKeys64-32 5000000 249 ns/op
// These tests do a lookup of keys already defined in the map per iteration.
// Regular Map backed by RWMutex
BenchmarkRegularStableKeysFound1-32 20000000 114 ns/op
BenchmarkRegularStableKeysFound2-32 10000000 203 ns/op
BenchmarkRegularStableKeysFound4-32 3000000 460 ns/op
BenchmarkRegularStableKeysFound8-32 2000000 976 ns/op
BenchmarkRegularStableKeysFound16-32 1000000 1895 ns/op
BenchmarkRegularStableKeysFound32-32 300000 3620 ns/op
BenchmarkRegularStableKeysFound64-32 200000 6762 ns/op
// Sync Map
BenchmarkSyncStableKeysFound1-32 5000000 357 ns/op
BenchmarkSyncStableKeysFound2-32 3000000 446 ns/op
BenchmarkSyncStableKeysFound4-32 3000000 501 ns/op
BenchmarkSyncStableKeysFound8-32 3000000 576 ns/op
BenchmarkSyncStableKeysFound16-32 2000000 566 ns/op
BenchmarkSyncStableKeysFound32-32 3000000 527 ns/op
BenchmarkSyncStableKeysFound64-32 2000000 873 ns/op
*/
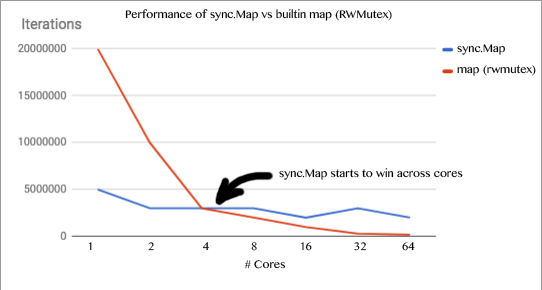
正如您立即看到的那样,我们的 regular map 具有出色的性能,它受 RWMutex 保护。事情进展顺利直到我们开始达到 4 个核心。此时不仅争用成为问题,而且跨核心的缩放因子也成为问题。RWMutex有太多的读取冲突,以至于当达到 32 个核心标记时,性能会受到很大影响。源代码地址 https://github.com/deckarep/sync-map-analysis.